

The AI landscape is evolving rapidly, and DeepSeek is at the forefront of this transformation. DeepSeek-V3 on 26th December 2024 and DeepSeek-R1 on 20th January 2025. But what makes these models so groundbreaking? Let’s dive into why DeepSeek is making waves and is a game-changer in artificial intelligence.
Updated on Jan 28: Downloads for the app exploded shortly after DeepSeek released its new R1 reasoning model on January 20th, followed by Nvidia’s share price dropping over 12 percent.
Despite the USA's restrictions on AI chip exports to China, DeepSeek has managed to innovate and thrive within these limitations. So, the question is: How did they do it?" It puzzles me as well.
DeepSeek is open-source, similar to Facebook’s LLaMA, unlike ChatGPT, which remains proprietary and unavailable on platforms like Hugging Face. What truly sets DeepSeek apart is its cost-efficiency. While training GPT-4 reportedly cost $100 million+, DeepSeek−V3 was trained for just $5.5 million.
HuggingFace link for DeepSeek-V3 & DeepSeek-R1 models.
Model Overview
DeepSeek-V3
A 671B parameter Mixture-of-Experts (MoE) model with 37B activated parameters per token. It features innovative load balancing and multi-token prediction, trained on 14.8T tokens. The model achieves state-of-the-art performance across benchmarks while maintaining efficient training costs of only 2.788M H800 GPU hours. It incorporates reasoning capabilities distilled from DeepSeek-R1 and supports a 128K context window.
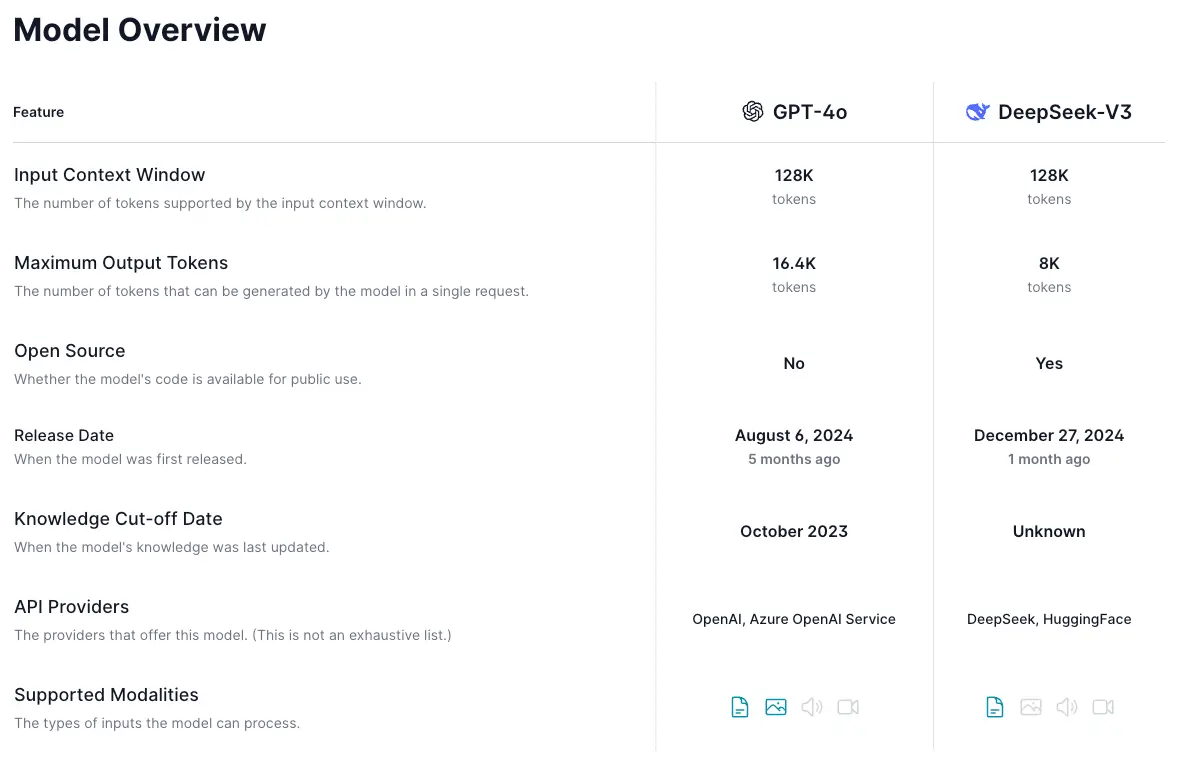
DeepSeek-R1
A 671B parameter Mixture-of-Experts (MoE) model with 37B activated parameters per token, trained via large-scale reinforcement learning with a focus on reasoning capabilities. It incorporates two RL stages for discovering improved reasoning patterns and aligning with human preferences, along with two SFT stages for seeding reasoning and non-reasoning capabilities. The model achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks.
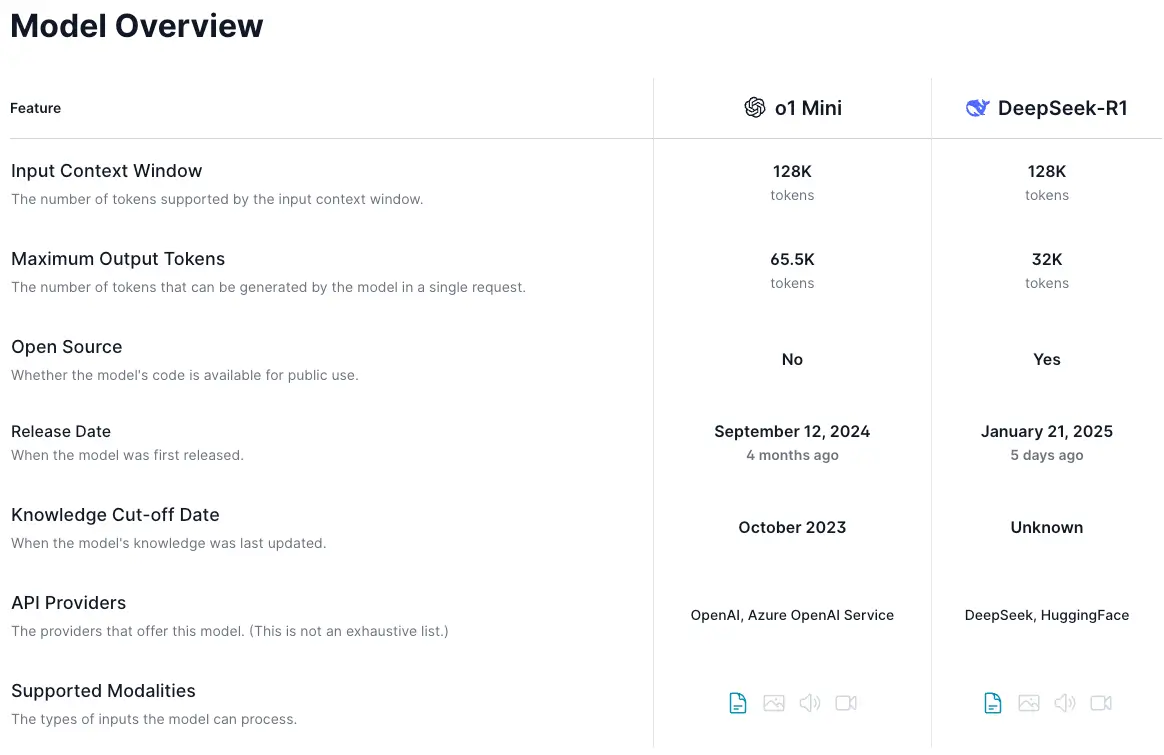
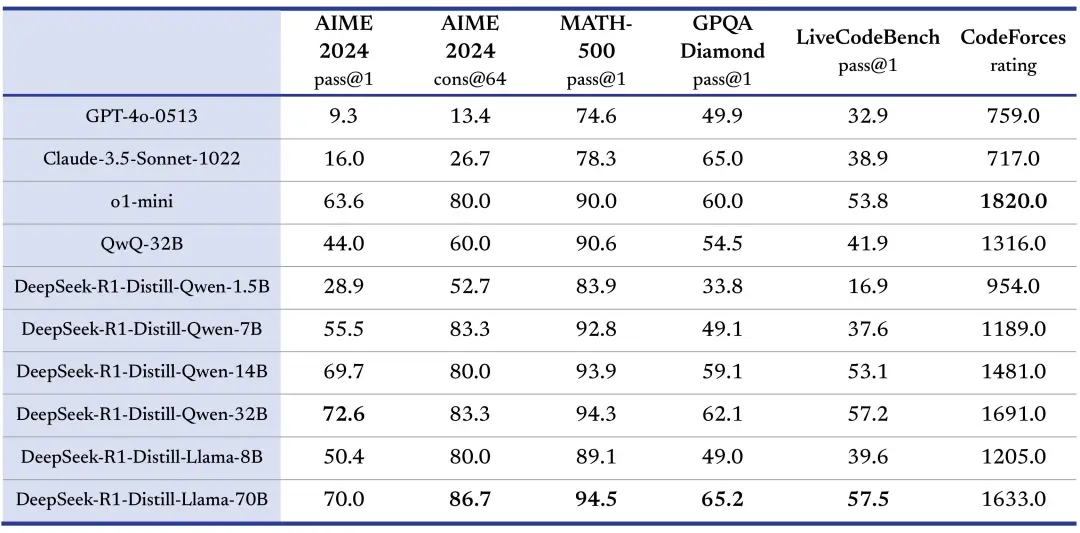
Benchmark
Deepseek R1 outshines QwQ, Llama 3.1, Claude 3.5, and the king of AI GPT-40 and o1-mini in many benchmarks metric.
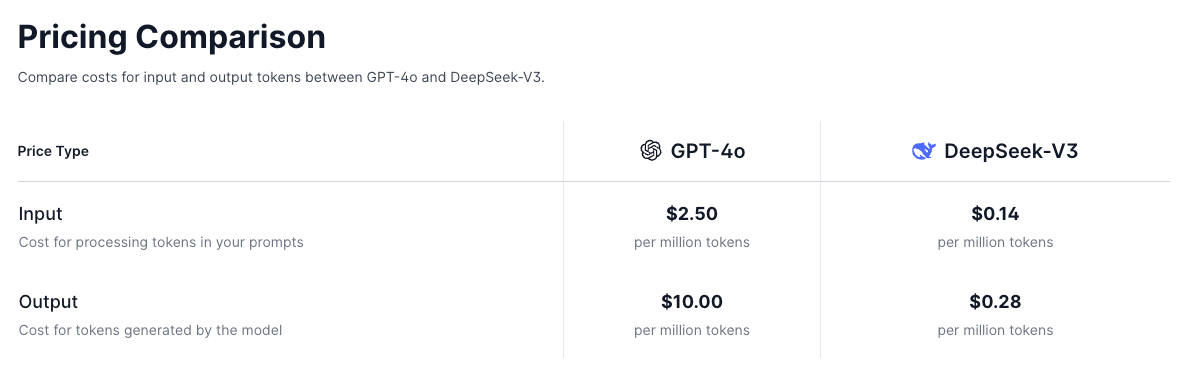
Price Comparision
DeepSeek-V3 vs OpenAI GPT-4o
DeepSeek-V3 is roughly 29.8x cheaper compared to GPT-4o for input and output tokens. Seriously cheaper btw.
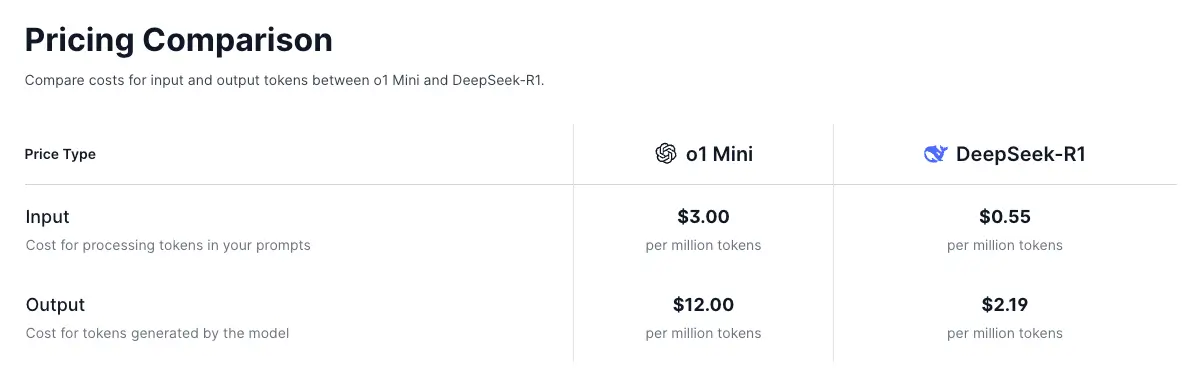
DeepSeek-R1 vs OpenAI o1-Mini
DeepSeek-R1 is roughly 5.5x cheaper compared to o1 Mini for input and output tokens.
Summary
DeepSeek-V3 and R1 are revolutionizing AI, setting new standard, and pushing the limits of performance and affordability with open-source access unmatched cost-efficiency, and cutting-edge performance. While DeepSeek-V3 delivers state-of-the-art results at just a $5.5 million training cost, DeepSeek-R1 excels in advanced reasoning tasks. Both models outperform competitors like GPT-4o and Claude 3.5 in benchmarks, offering 29.8x and 5.5x cost savings respectively. DeepSeek is redefining the AI landscape by making high-performance AI affordable and accessible to all.
What are your thoughts, will China take the lead on AI?
Related:


